

Machine Learning : Convolutional Neural Network
Intro
- 與神經網路類似, 但使用卷積取代權重向量
- 原本每層是 Perceptron -> Activation
- 現在變成 Convolution -> Activation -> Pooling
- 相對於NNet的參數量更少
Convolution
- 每個kernel(filter) 去跟 feature map 的對應區域做矩陣乘法
- 乘完之後移動,步數由stride決定
- e.g. input=6x6, kernel=3x3, stride=1 -> 4x4 feature
- 可以使用超過一個kernel,就會增加feature的第三個維度 (2 kernel -> 2x4x4 feature)
例如 : RGB 3 channel
經由卷積層之後,下一個node相連的參數與kernel size相同,因此可以減少參數量
Pooling
這邊以Max Pooling為例
- 根據一個window去取區域內的最大值
- 可以做到降低特徵圖大小 -> subsampling
- 因保留最大值,最重要的特徵還是在,而且可以保持平移不變
- 減少參數量
Back Propagation (DL)
遵循以下公式:
其中:
- eta為學習率,用來控制更新幅度
- alpha為動量,用來減少震盪
- lambda為權重衰減,用來防止overfit
傳統的最佳化使用梯度下降,引入momentum後,若這次負梯度方向與上次更新方向相同,則做疊加-> 達成加速收斂
一些名詞定義
- Epoch : 讓資料在模型中往前、往後(到底)一次
- Batch size : Data set可能很大,先把它分成mini batch (64, 256, …)
- Iterations : 跑完一個epoch會用到的迭代次數
對抗過擬合
- Dropout : 隨機關閉神經元,生成網路的一個subset
- Weight Decay : 額外懲罰太大的權重,縮小規模
- Data Augmentation : 對有限的資料集做變化,讓模型學到更多不同變化(裁切,翻轉,模糊…)
Cross Entropy
單純的去計算分類錯誤的比例不夠準確,因此引入交叉熵 :
當答對時,loss為0,反之會很大,因此最小化loss就可以逼近正確答案
Softmax
把模型的輸出(分類結果)最後再套一個softmax,轉換成機率表示:
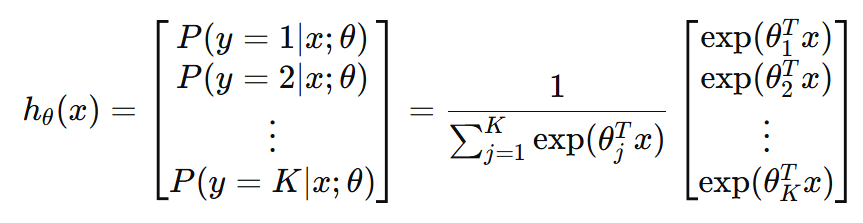
因為是透過所有類別的指數值相加後正規化,保留分類的特性,但是又可微分
CNN examples
Lenet-5 (Lecun-98)
Convolutional Neural Network for digits recognition
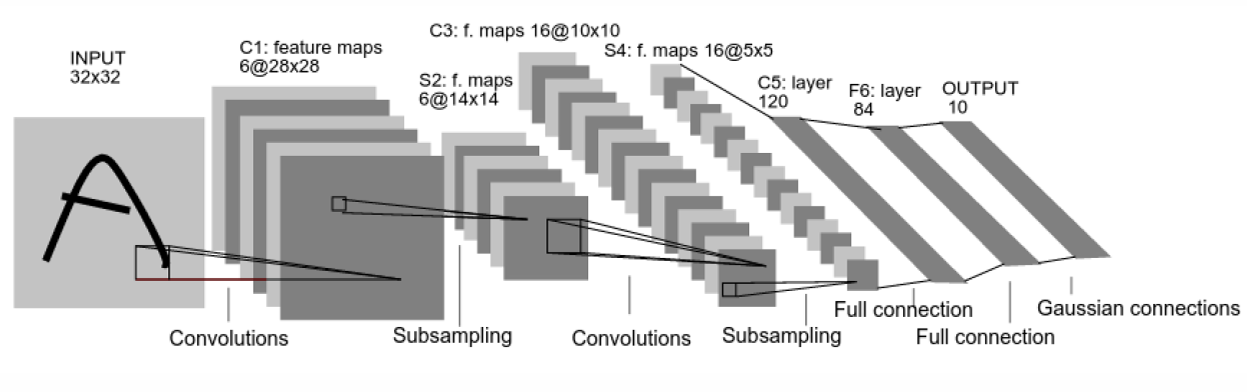
其中:
- 捲積層用於採樣
- 子採樣層用於降維(避免overfit)
- 最後再套FC + softmax完成後處理
AlexNet

- 在CNN的基礎上,每個Layer再加Local Response Norm,模仿生物視覺神經對局部抑制的現象
- 在FC層用ReLU,加速收斂
VGGNet
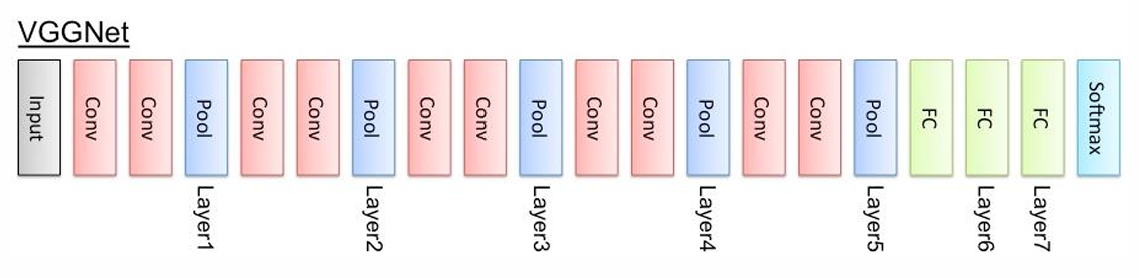
在AlexNet的基礎上作改良:
- 使用Block堆疊卷積層,每個區塊的尾端才做Pooling
- 網路更深 -> 提取的特徵更多
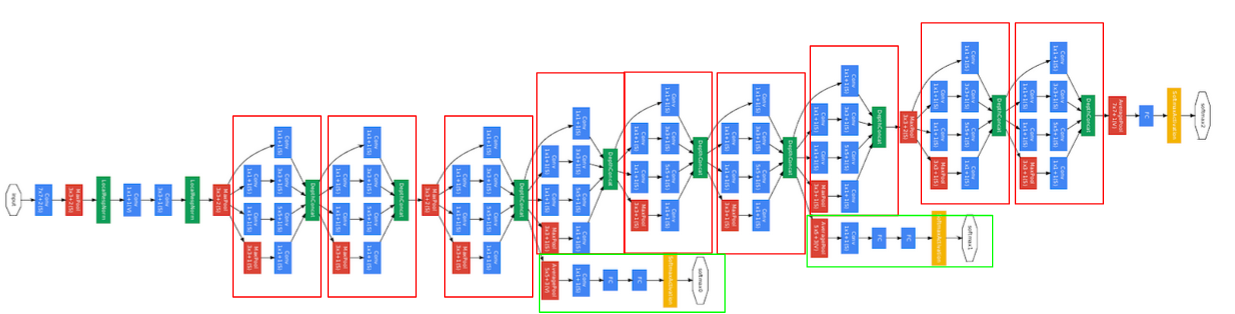
GoogleNet
前幾層都是傳統的卷積+池化,後面再接新概念Inception:
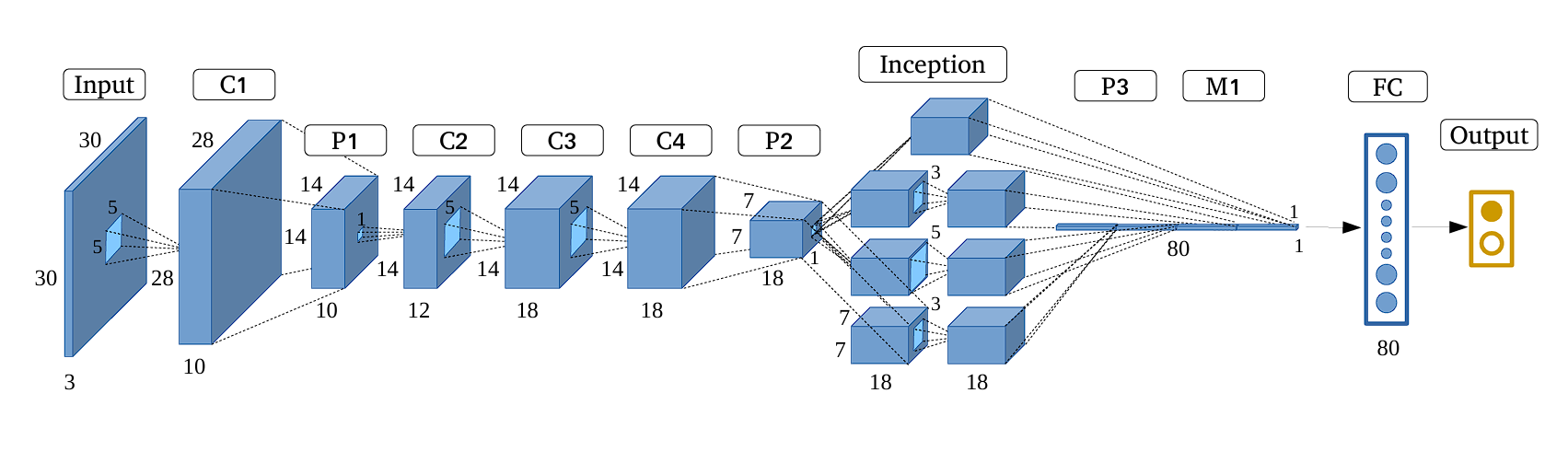
Inception其實就是在同一層中探索多種卷積核大小的特徵表示:
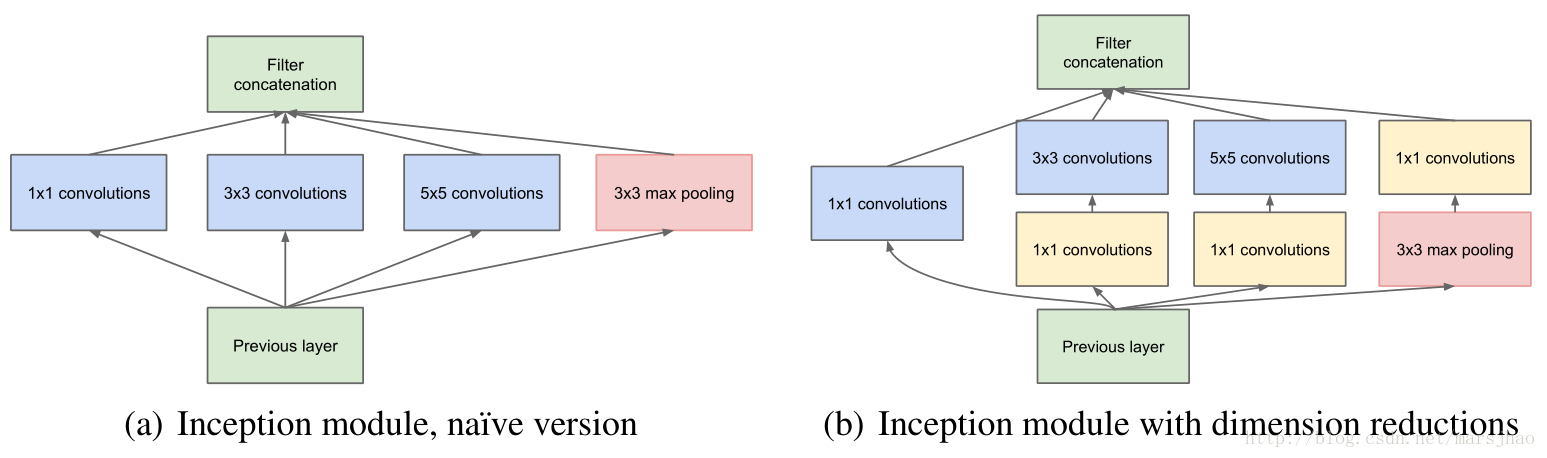
採用四條平行路徑,最後再concate在一起(左邊的實作)
但這樣的方式會導致計算成本太高 (3x3, 5x5)
所以在所有的3x3以及5x5之前先使用1x1卷積進行降維,減少參數量,同時也在3x3 Max Pooling之後多套一次卷積,增加非線性表示能力
完整的模型架構圖:
ResNet
Intro
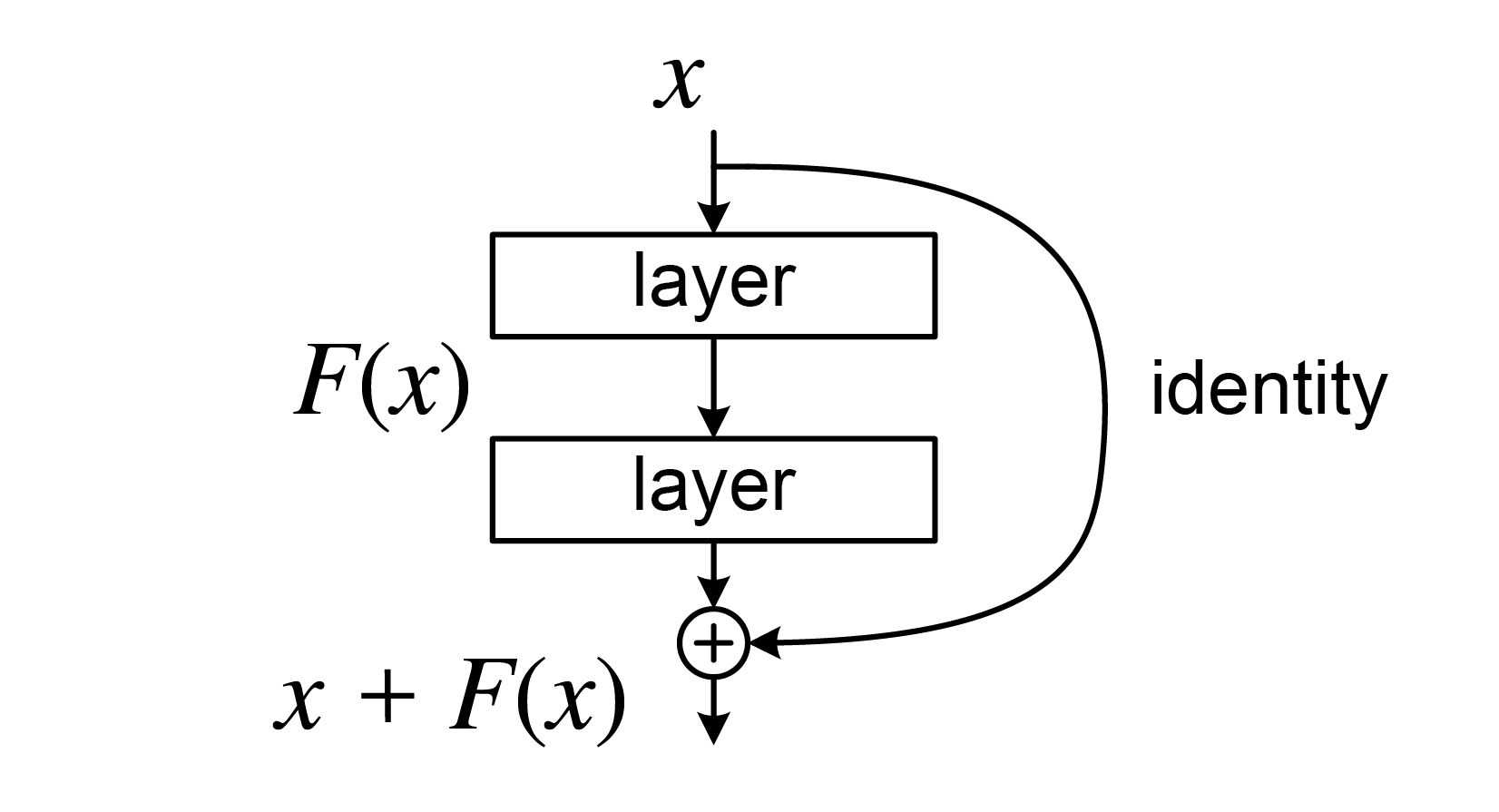
傳統的卷積網路如果一直堆疊layer會導致更高的loss,於是就有殘差學習法:
在第二層的Activation之前先把輸入shortcut過來,讓模型有學習identity的可能
讓模型學會不要動
Deep ResNet
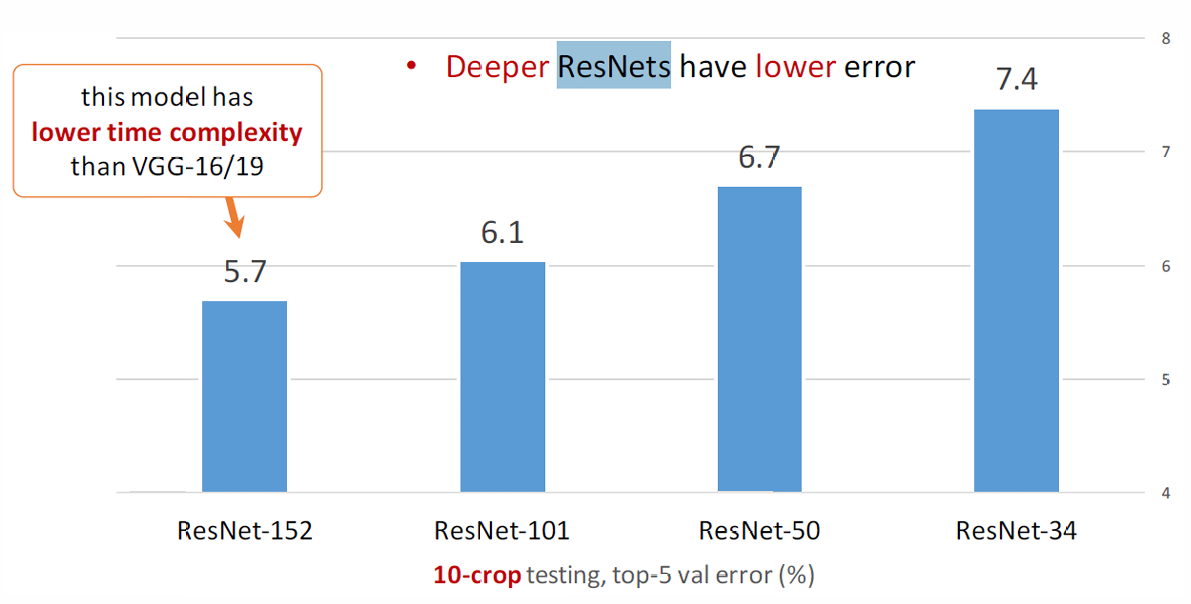
更深的ResNet在表現上反而更好,且複雜度也比傳統CNN更優(VGG, …)
DenseNet
基本上可以算是ResNet的加強版,每層都shortcut到他後面的所有層
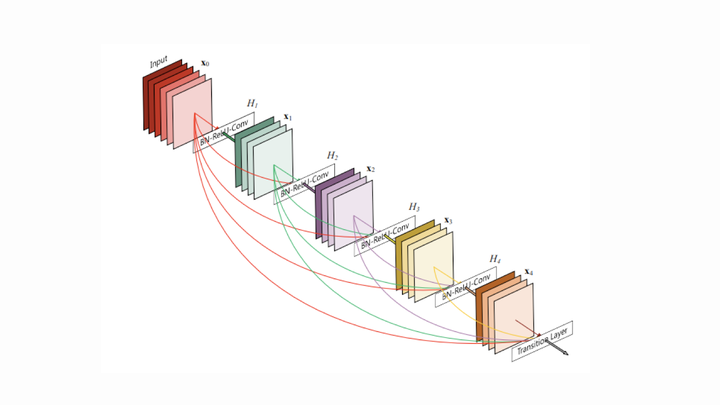
這樣實作帶來的好處:
- 梯度不容易消失
- 更強的特徵傳導(比ResNet更強)
不過記憶體消耗非常大,且計算成本很高,因此實務上以ResNet為主(Trade-off效益太低)
Applications of CNN
通常用作以下幾類任務:
- 圖片分類
- 人臉辨識
- 重識別(Re-ID)
- 物件偵測
- 動作辨識
- 圖片分割
- 場景分析
Classifications
Binary Classification的結果通常分為:
- True positive(TP) (good)
- False positive(FP) (bad)
- True negative(TN) (good)
- False negative(FN) (bad)
然後可以定義以下評價指標:
- 準確率
- Recall (靈敏度/真陽性率)
- True positive rate = Recall
- False positive rate
Multi-Scale Deep Learning
當輸入的圖片解析度為固定時普遍採用
相較傳統CNN,使用不同解析度去抓不同尺度下的特徵:
- 訓練多個解析度下個CNN
- 每個解析度獨立通過一個網路
- 透過Unified Structure做統整,接著繼續(分類任務, …)
Multi-Model Deep Learning
- 整合不同類型的資料(圖片, 文字, …)
- 不同模態的資訊可以互補,有助提升分類能力
Multi-Task Deep Learning
- 共用特徵提取的部分
- 後面並聯多個分類器
- 每個任務的特徵可能可以互補,且這樣做效率更高
Face Recognition
需要先偵測臉部區域,接著做對齊之後,才做Matching
DeepID
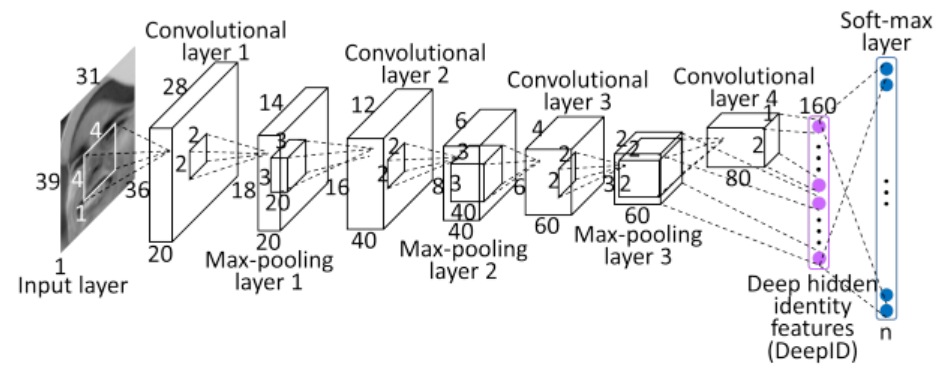
DeepID 1
- 五個關鍵點 : 兩眼、鼻尖、嘴巴兩端
- 做仿射讓整體對齊
- 接著取10個區域,2種scale,再算上RGB就有 個patch
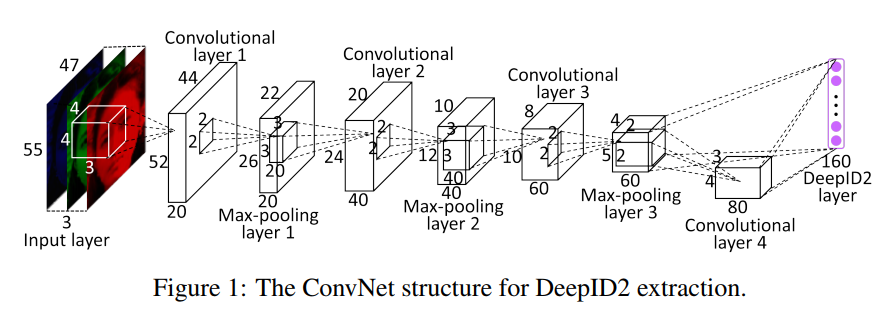
DeepID 2
- 相較1,從臉部圖像中裁切出200個patch最後選25個
Loss Function上 加了 Face Verification Signal,把他跟原本的Identification Signal做加權
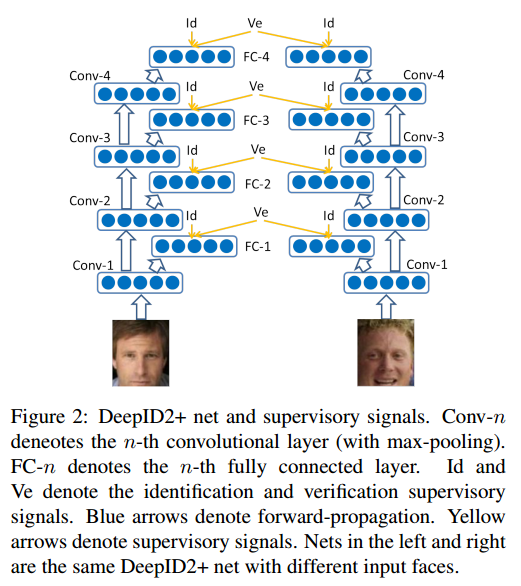
DeepID 2+
- 資料集使用CelebFace + WFRef,更大了(~29k張圖片)
- 多層 supervision (FC+Softmax)
- Binary Features Encoding,比對速度更快
- 遮蔽容忍力更高,遮蔽將近一半仍有90%準確率
DeepID 3
- 基於2+,再額外加上更多layer
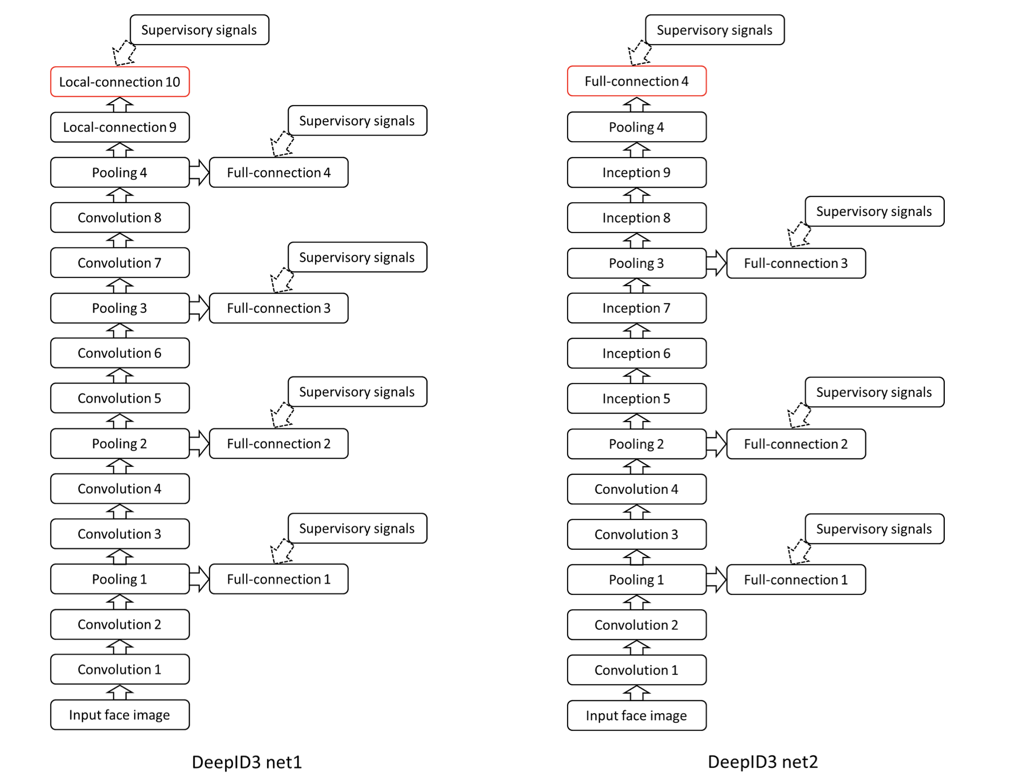
Deep Face
- 偵測臉部並標記關鍵點
- Frontalization
- 將人臉轉換為 4096 維的向量

- DeepFace 已經非常接近人類準確率
FaceNet
- 超大資料集(~260M)
- Deep Architecture
- 在L2正規化後使用Triplet Loss (直接用分類方法會導致Softmax爆炸)

Baidu
- 多視角特徵提取
- 大資料集(~1.2M)
- 每個patch一個CNN網路
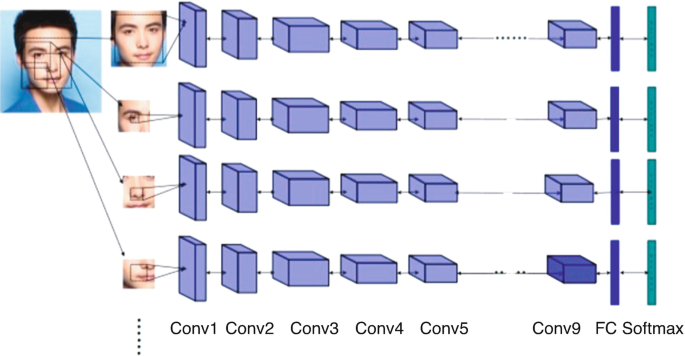
Re-identification
主要目標是辨別同一個物件在不同角度下(不同攝影機角度)是否為同一個。可以用在行人、交通工具、人臉,…
解法 : Feature Matching
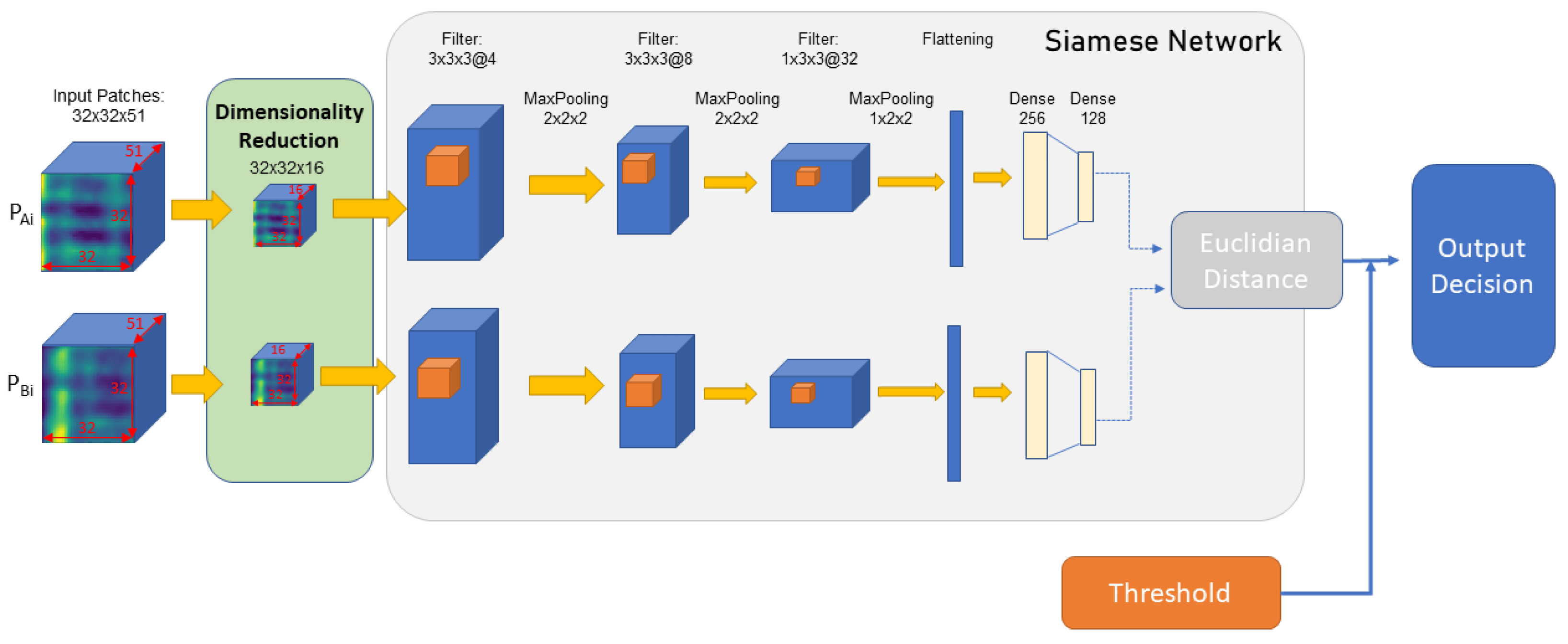
- 套用相同的神經網路之後,再計算特徵向量的L2距離(歐幾里得距離) :
- 引入Hinge Loss,對於相似度很低(如:方向不同),若輸出與邊界的距離小於定值就懲罰 :
- 反之(很相似的圖片),則目標就變成最小化兩者距離 :
Loss Function Design for Feature Matching
CNN的全接層通常是套Softmax,但Softmax的用處在懲罰錯誤的分類(類間差異),無法處理類內差異,因此需要設計可以處裡的loss function :
Triplet Network & Triplet Loss
- 同類樣本彼此更近,異類樣本更遠
- 強制Anchor與Positive的距離、Anchor與Negative的距離至少一個 margin
Large Angular Margin Softmax Loss
- 相較Softmax, L-Softmax在特徵分布上更明顯
- 把Softmax改成Cosine form,最大化 的餘弦值()
- 加入更大的角度懲罰,讓夾角放大m倍 :
- 其中 的定義如下(使用分段函數,因為餘弦不是單調函數,會沒辦法保證連續可微) :
Center Loss
- 增加類內聚合性
- 通常搭配Cross Entropy Loss
Sphere Loss
- 把特徵向量與權重都映射到單位球面
- 類間角度最大化
- 類內角度最小化
先做L2 Normalization :
處理內積 :
Loss Function :
Object Detection
- 在一個圖片中偵測(多個)物件
- 多個目標物件、畫面中也有多個物件
通常使用One stage detection,或是Two stage detection。又可以做以下的區分 :
- Two stage
- RCNN (Region-based Convolutional Networks)
- Fast RCNN
- Faster RCNN
- One stage
- YOLO (You Only Look Once)
- SSD (Single Shot Detector)
RCNN

一開始的RCNN :
- 提出約 2000 個 Region Proposals
- 每個Region分別被裁切與Warp成 227×227 大小,單獨丟進CNN提取特徵
- SVM為每一個類別訓練分類器
- Bounding Box Regressor精調邊界框
但模型的訓練速度太慢、且需要花費大量記憶體,因此有了Fast RCNN (主要變快的因素是共享feature map):
- 整張圖像只經過一次 CNN
- Region Proposals(RoIs)映射到 Feature Map 上 (RoI Pooling)
- 套FC,再並聯兩個輸出(Softmax + Bounding Box)
之後又有人想到用Region Proposal Network去做候選框,所以有了Faster RCNN :
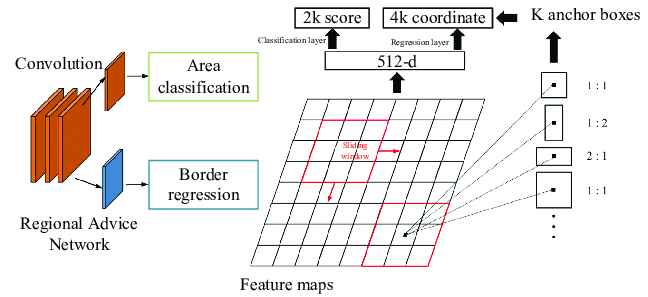
Faster RCNN 完全不需要external region proposal,前兩者生成候選區域都需要(Selective Search),且RPN會產生有用的proposals,進一步加快訓練速度
YOLO
Two stage detection還是不優,因為訓練的過程很複雜,而且模型執行速度又很慢,因此有了One stage detection
相較於RCNN需要Selective Search去生成一堆候選區域,YOLO一次性輸出所有物件的位置,主要遵循以下步驟 :
- 圖像切割與 grid cell 建立
- 每個cell預測bounding boxes與confidence
- 合併所有bounding boxes並篩選
- 類別機率與分類
- 將bounding box預測結果 與grid cell分類結果 結合
雖然YOLO很快,但是因為cell的限制很難偵測小物件,而且相對於RCNN系列loss更高(定位不準確)
Action Recognition
Action Recognition非常難,主要因為 :
- 複雜度(主因)
- 上下文對應的類別難以定義
- 沒有基準資料集(deprecated)
比較常見的幾種方法 :
Single Stream Network
- Single Frame:單張影像做分類,沒有時間資訊
- Late Fusion:多張圖像分別經過CNN
- Early Fusion:多張圖像在輸入時就融合
- Slow Fusion:介於 Early/Late 之間,隨著層數加深慢慢融合時間資訊
此方法無法擷取複雜動態
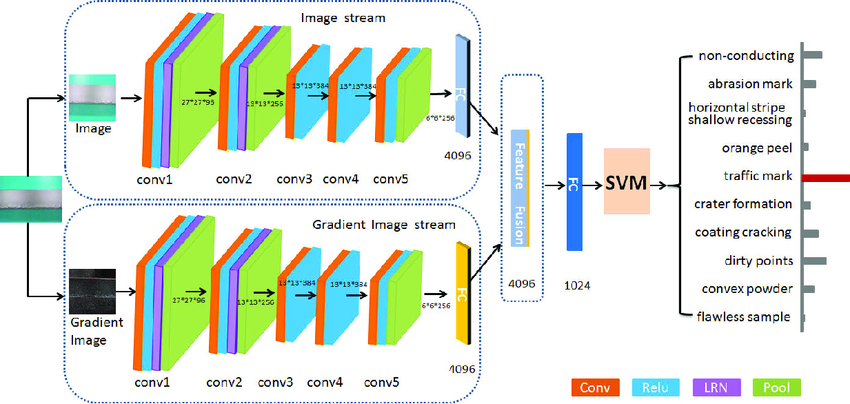
Two-Stream Network
- Spatial stream:處理靜態影像資訊
- Temporal stream:處理動態資訊
- 最後再套SVM或Softmax
Recurrent Themes
- LSTM:CNN 擷取每張圖像特徵 → LSTM 負責時間序列建模
- 3D ConvNet:直接用 3D kernel 一次卷積整個影片序列
- Two-Stream:同上
- 3D-Fused Two-Stream:Two-Stream 的輸出再進 3D ConvNet 融合
- Two-Stream 3D ConvNet:兩條流各自用 3D CNN 提取時間-空間特徵再融合
LRCN(Long-term Recurrent Convolutional Network)
- 每一張影像用CNN萃取視覺特徵
- 再用LSTM處理序列學習
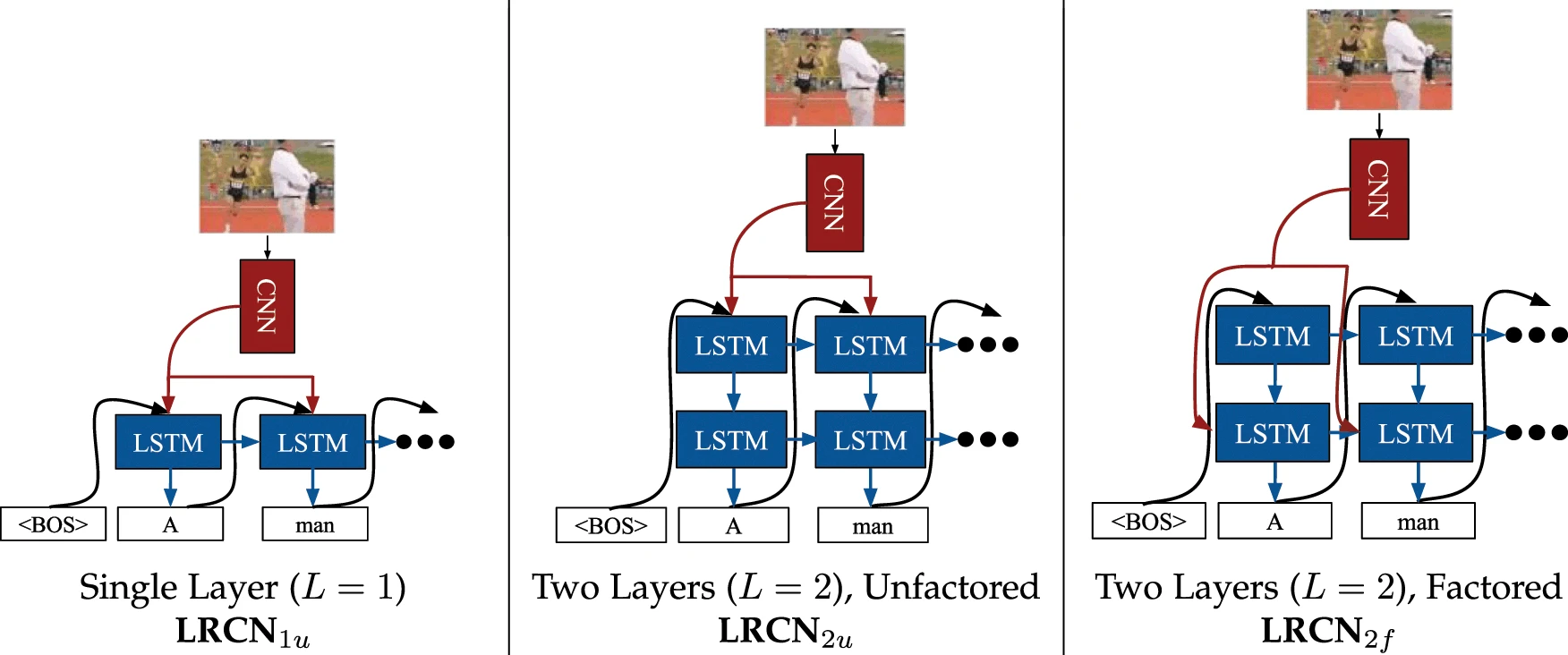
Image Segmentation
分為語意分割、實例分割
- Semantic Segmentation : 辨識出每一個像素所屬的類別
- 每一種物體的像素被塗上同樣的顏色
- 不區分同類物體之間的實例
- Instance Segmentation : 在語意分割的基礎區分出每一個獨立的實體物件
- 不同的同類物體會有不同顏色
- 像素進行更細緻的標註(bounding box)
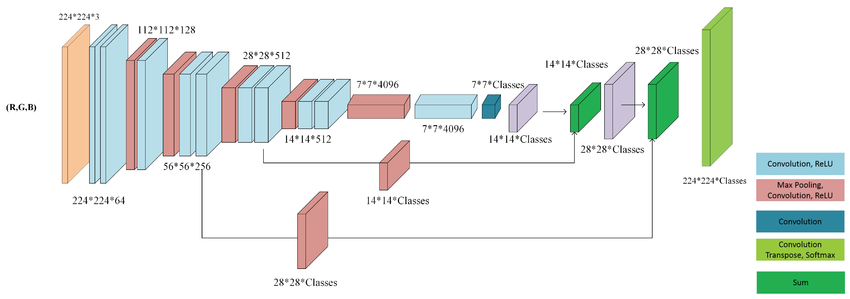
Fully Convolutional Networks
- 全連接層改為卷積層 -> 逐像素分類
- 小物體容易被忽略(Downsampling)
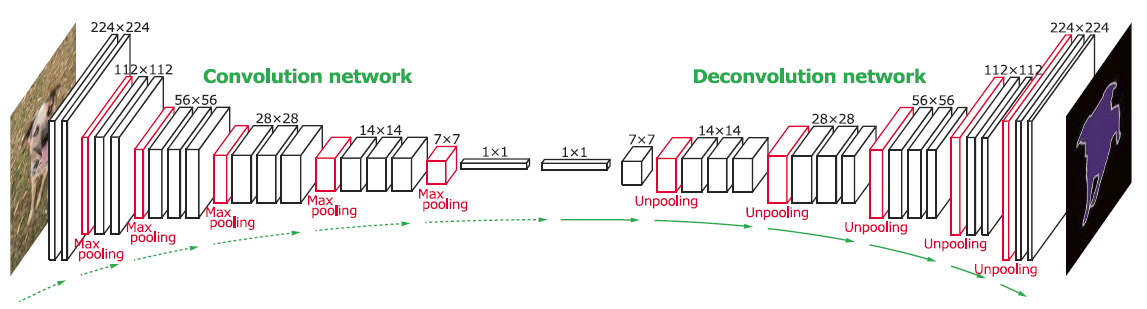
DeconvNet
- Convolution Network + Deconvolution Network
- 還原能力更強
- 訓練成本較高
UNet
- Encoder-Decoder對稱結構 + Skip Connections -> 保留原圖細節
- 訓練快、收斂快、結果清晰
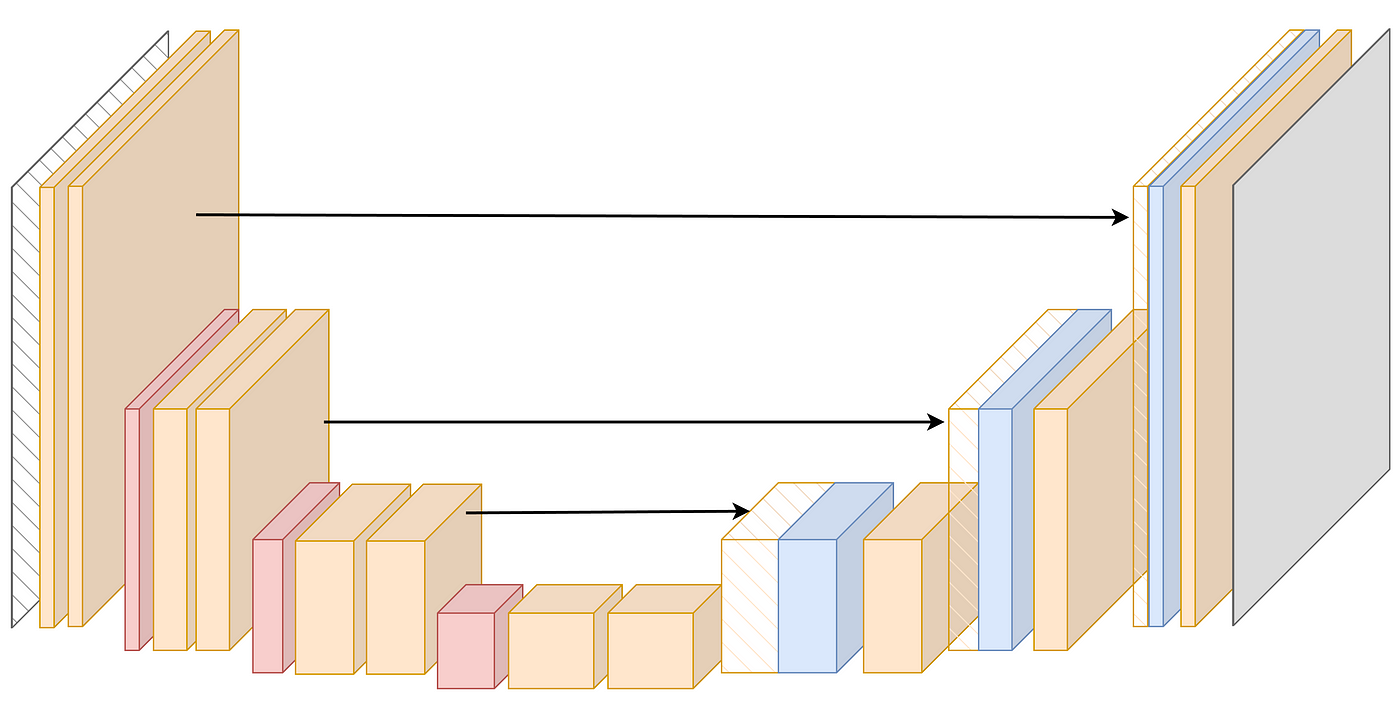
Scene Analysis
- 從單張或多張影像中分析室內場景的空間結構
- 地板、牆壁、天花板, …
- 推論出牆面與地板的交界線
- 基本三維空間
- 完整3D layout
Deep Networks for Surface Normal Estimation
- Global:結構與物件表面法線之關係
- Local:捕捉局部細節,邊緣資訊
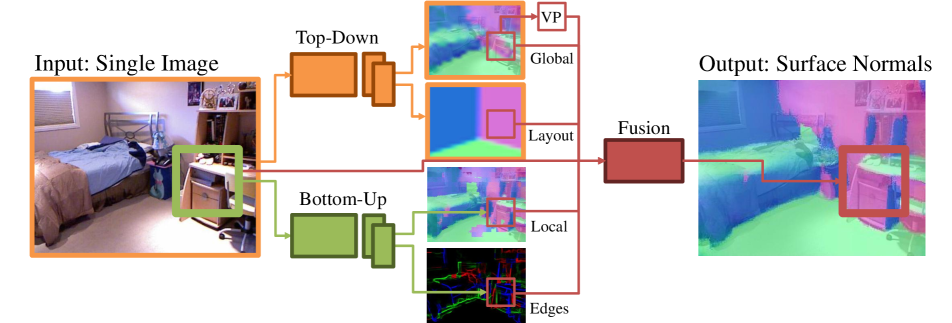
Coarse-to-Fine Indoor Layout Estimation (CFILE)
- CNN提取特徵
- Coarse Layout
- Critical Line Detection
- 建構 layout
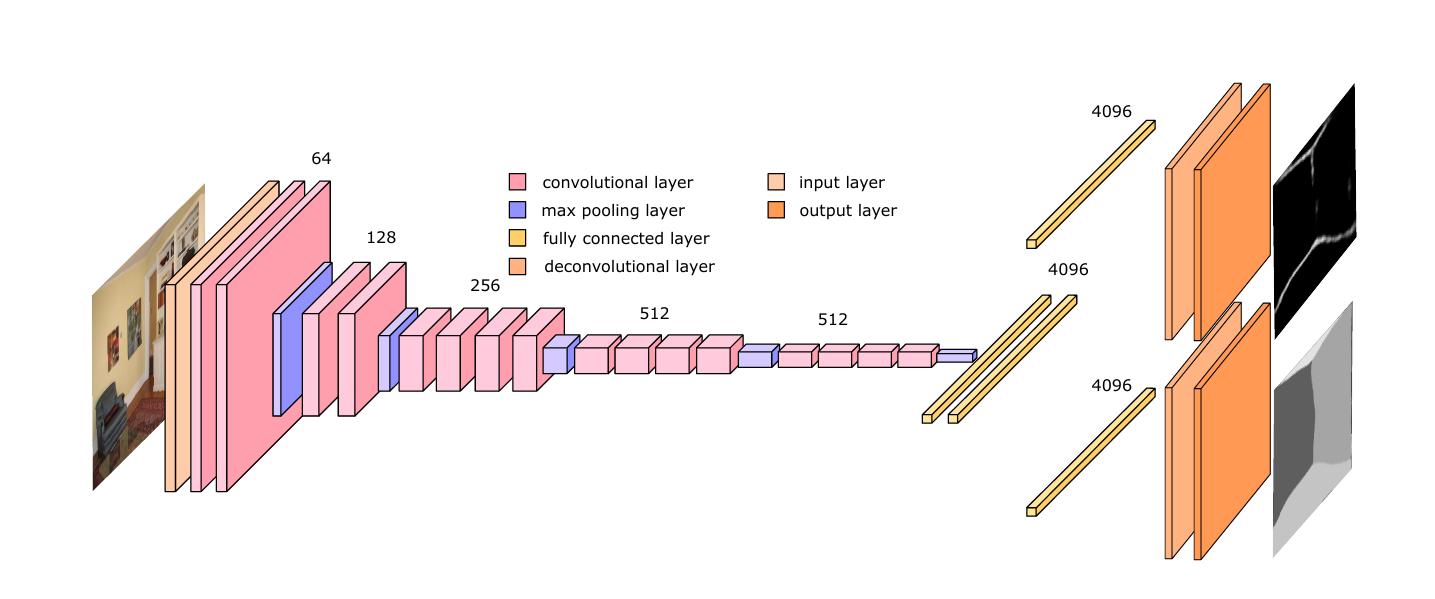
Depth and Surface Normal Estimation
此模型用於從單張 RGB 圖預測深度或表面法線
- CNN提取特徵(patch-based)
- 多層FC(回歸)
- 使用條件隨機場(CRF)進行後處理
- 強化預測一致性
Some content may be outdated