

Pixiv - KiraraShss
Welcome to my blog
585 words
3 minutes
Machine Learning : Transformer
先從Auto Encoder開始
- 透過兩組神經網路學習資料的特徵表示法
- 透過decoder盡可能還原輸入

Intro
-
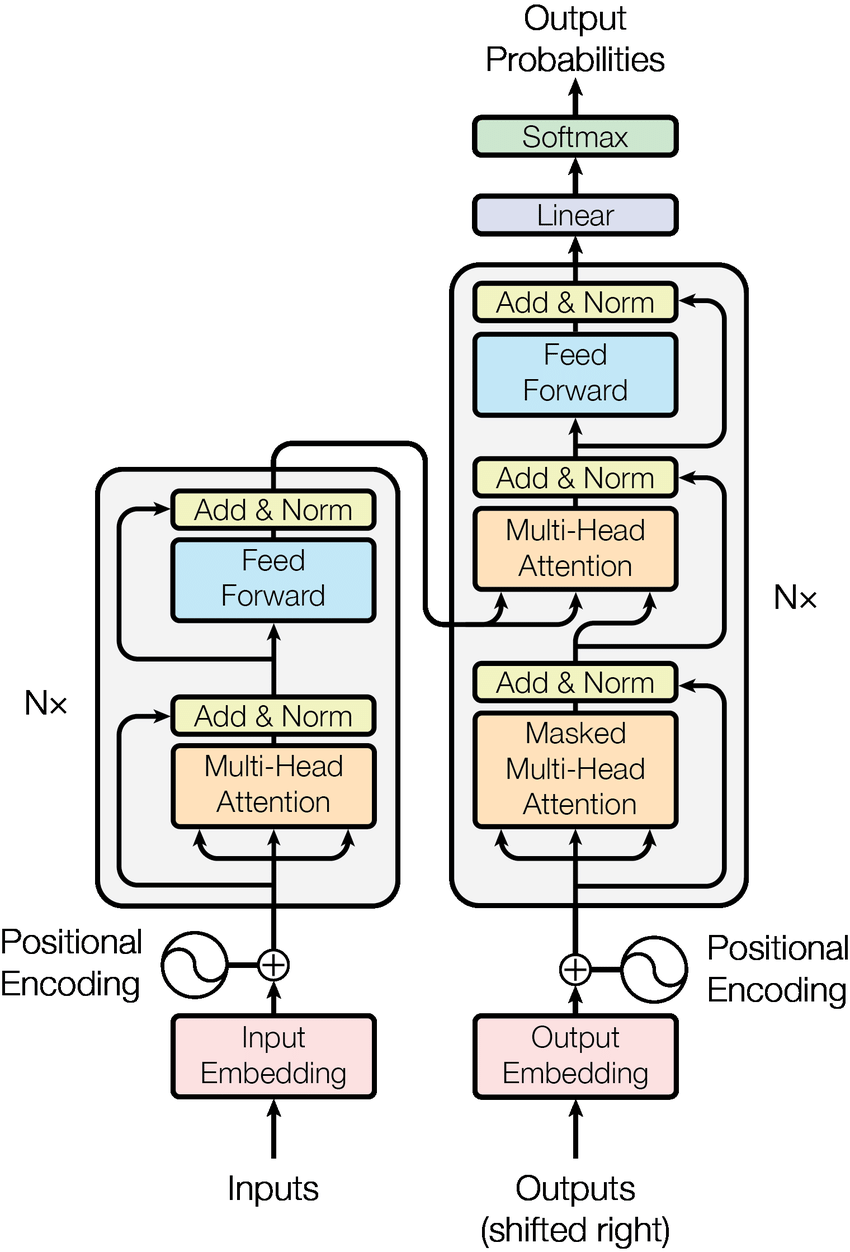
由很多部件組成,部件形成一些Block (encoder block, decoder block),堆疊這些block形成encoder, decoder
a -
Encoder & Decoder + Attention
-
Encoder接收序列資料,透過位置編碼輸入模型,並產生Context Vector
-
Decoder接收右移過的decoder輸出 (自回歸),並結合Encoder的Context Vector (注意力)
Embedding
- Word Embedding : Bagging / Word2Vec
- Positional Embedding : 可以用訓練或是公式
最後將兩者相加,得到輸入的向量表示法,用來餵給Transformer
Attention
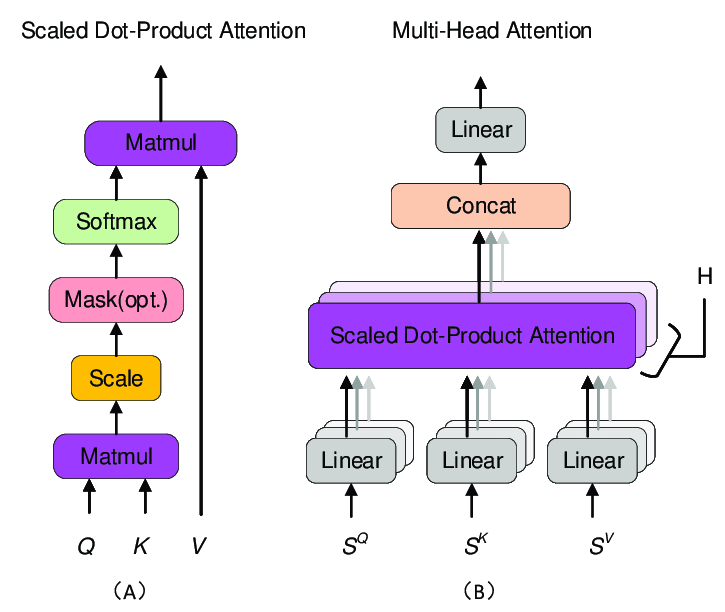
Scaled Dot-Product Attention
- QKV矩陣 (Query, Key, Value)
- 最終的Attention Score是Value的加權和
- Value為Key與Query的相似度,而不同的Q會產出不同的注意力 (Query Driven)
- : 相似度
- : 縮放,用來防止梯度消失
- : 算出權重 (Softmax 歸一化) + 得到最終輸出
Multi-Head Attention
- 先把 投影,再做次注意力(投影到個子空間)
- 算完之後做Concat,接著線性變換回原本的空間
- 模型去學習,還有 (最後的線性變換) 的參數
Masked Attention
- 避免模型看到之後的資料
- 乘上一個非常小的權重,讓Softmax輸出為0
Add & Norm
- 殘差連接 (學習輸出不變的可能性)
- 提升泛化能力
Feed Forward
- 兩層FC,第一層是ReLU,第二層不激活
Decoder Attention
1 : Masked Multi-Head Attention
- 讓模型只使用之前的資訊 (根據之前的翻譯,推得現在的翻譯)
- 做的計算,然後在Softmax之前進行Mask
2 : Multi-Head Attention
- 這邊接入了Encoder的輸出
- 根據算出,
- 根據上一個Block的輸出計算
- 這邊接入編碼器的輸出,是從原文得來的,所以不用Mask
3 : FC + Softmax
- 經過Feed Forward後進入FC
- FC做線性變換投影到詞彙表
- 輸出矩陣做Softmax,因為Mask所以每一行對應那個位置的單字
- 最後的機率拿來做預測
與CNN的比較
- CNN一次只能看一個Window, Transformer可以看到全局資料
- CNN的多通道也可以用多頭注意力來模擬
Reference
Machine Learning : Transformer
https://blog.cyberangel.work/posts/machine-learning-transformer/ Last updated on 2025-05-31,187 days ago
Some content may be outdated