

Pixiv - KiraraShss
Welcome to my blog
860 words
4 minutes
Machine Learning : Generative Model
Generative Adversarial Network
Intro
- 把一些雜訊隨機映射到圖片裡面
- Generator : 學生,生成圖像
- Discriminator : 老師,判別圖像是不是假的
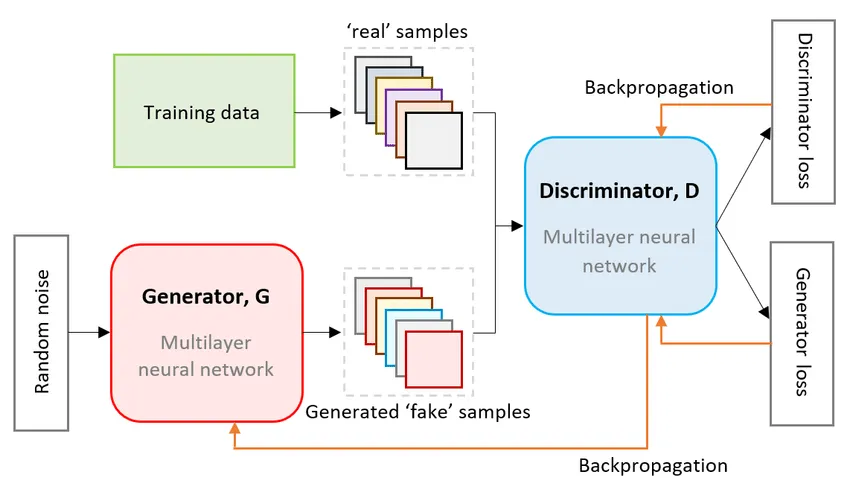
Generator
- 神經網路
- Input : 高維度向量(雜訊)
- Output : 圖像
- 輸入向量的每個維度代表某些特徵
Discriminator判別器
- 也是個神經網路
- Input : 圖像
- Output : 標量值
- 用來判斷Generator的輸出是真的還是假的(打分數)
對抗式訓練流程
- 初始化Generator, Discriminator
- 進入循環,每個epoch重複 :
- 固定G、更新D,學習給真實物件高分 :
- 固定D、更新G,學習產生可以騙過D的圖片 : 最小化 ,
Loss Function
- MinMax函數 :
- D學會最大會欺騙能力
- G學會最大會欺騙能力
GAN Structured Learning
Structured Learning
- 輸出 : 序列、矩陣、圖形、樹
- Translation / Speech Recognition / Text to Image …
Challenge
- One-Shot / Zero-Shot Learning
- 輸出空間太大 (很多類別沒有訓練資料)
- 規劃能力?
- 組件依賴性?
GAN
- Generator : 只用來生成(組件級生成)
- Discriminator : 用來整題評估,找出最優解(planning)
Generator / Discriminator learn by itself
Generator
- 深度網路也可以拿來生成 (Recall : Auto-encoder)
- 只能模仿外觀,難以學習組件關聯 (無腦堆疊會導致無法訓練/過擬合)
Discriminator
- 考慮整體畫面
- 生成問題 (負樣本從哪來?)
Mode Collapsing
- 生成器只學到部分模式(容量不足)
- 多樣性不足(泛化能力差)
Conditional Generation by GAN
- Text-to-Image
- 傳統監督 : 模糊圖像
- Conditional GAN : 判別器接收圖片與條件,判別匹配程度
- Image-to-Image
- 傳統監督(close) : 類似Auto encoder
- Conditional GAN : 判別labal與生成圖片是否為real pair
Unsupervised Conditional Generation by GAN
Direct Transformation
問題與解決
- 問題: 可能忽略輸入
- 解決方案:
- 網路設計避免問題
- 預訓練編碼器網路
- Cycle consistency
Cycle GAN
- 雙向轉換: 和
- 循環一致性損失
- Silver Hair範例
- StarGAN: 多域處理
Projection to Common Space
架構
- Domain X/Y各有Encoder和Decoder
- 共同潛在空間投影
- 重建誤差最小化
改進技術
- 參數共享: Couple GAN, UNIT
- Domain Discriminator
- Cycle Consistency: ComboGAN
- Semantic Consistency: DTN / XGAN
Applications
- Image Disentanglement車輛面向轉換
- 混合風格生成
- Collection style transfer
- Object transfiguration
- Season transfer
- Photo generation from paintings
- Photo enhancement
Diffusion Model
Intro
- 高斯分布映射到圖片分布
- Forward process & Reverse process
Forward Process
- 迭代式加入雜訊
- 線性排成
- 生成image pair用來訓練
- 克服GAN的一步生成困難
Training Denoising Model
- 用生出來有雜訊的image pair做訓練
- 所有步驟使用相同模型
Reverse Process
- 迭代使用去雜訊模型
- 從純雜訊恢復清晰圖像
DDPM (Denoising Diffusion Probabilistic Models)
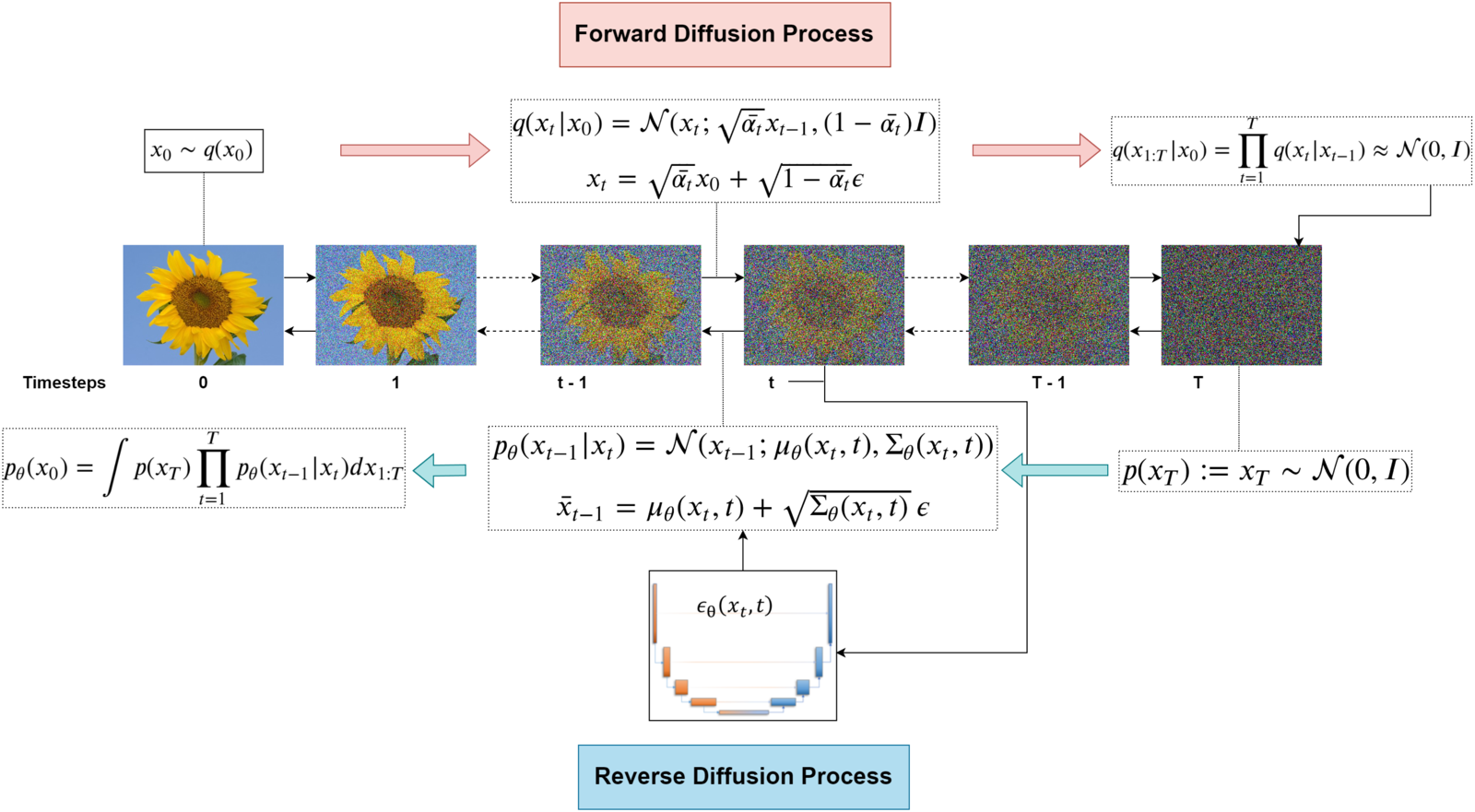
步驟索引t
- : 第t步的圖像
- : 清晰圖像
- : 純雜訊圖像
線性調度β_t
- 控制雜訊量的參數
- 隨t增大而線性增加
與GAN比較
共同點
- 目標相同: 生成真實圖像
- 應用領域重疊
擴散模型優勢
- 理論基礎: 隨機微分方程
- 只需訓練一個神經網路(通常U-Net)
- 避免GAN訓練問題
- 多層雜訊注入的強表達能力
評估指標
FréchetInception Distance (FID)
- 基於預訓練網路特徵
- 假設高斯分布
- 使用Fréchet距離
CLIP Score
- Contrastive Language-Image Pre-Training
- 4億圖像-文字對訓練
- 評估提示文字與生成圖像的特徵距離
Reference
Machine Learning : Generative Model
https://blog.cyberangel.work/posts/machine-learning-generative-model/ Last updated on 2025-05-31,187 days ago
Some content may be outdated