

Paper Review : Learning to Detect Memory-Related Vulnerabilities
Intro
Motivation
Memory-related Vulnerability可以大致理解為CTF中的Pwn相關Bug Pattern (Overflow, Use After Free, Out Of Bound, …),也有一些其他的例如Memory Leak, 不過大多數的類型都涵蓋在Pwn的類別。而在對CVE的分析中發現,在其中被回報的漏洞有四成左右都是記憶體相關弱點,因此成為許多研究的目標,主要可以劃分為以下幾個面向 :
- Core Problem : 記憶體弱點的重要性以及危害性。記憶體弱點大多數時候都可以造成RCE (假如是在Stack上甚至可以很簡單的控Return Address)或是DoS (讓服務崩潰)
- Context : 記憶體弱點出現的地方大多數都是C/C++這種低階語言,因為支援手動、未被抽象化封裝的記憶體管理(malloc, free),相比高階語言更加脆弱(error-prone)
- Goal : 在開發階段就及早偵測漏洞,去避免後續維護的成本。以藍芽為例,藍芽標準可能會有未定義行為(需要SDK去進行定義),再往下又會有硬體製造商SDK的軟體錯誤以及開發者所撰寫程式碼的錯誤。 在整條供應鏈中只要任何一個環節出現弱點,都會對下游的軟體造成重大危害,就算下游針對不安全的SDK進行防禦(Sandbox, Seccomp, …)仍然有可能被攻破(Tesla in Pwn2Own 2023,參考 影片)。 因此及早偵測漏洞成為有價值的研究點
Existing Approaches
目前主流的漏洞分析主要為以下幾個方式 :
- 傳統的Static Analysis : 通常就是漏洞研究員在做的事,不過人工分析往往離不開以下幾個問題 :
- 極度仰賴既定的Pattern去做分析,可能沒辦法覆蓋所有可能的弱點
- 需要大量知識,若經驗不足可能無法正確識別漏洞,且需要花費成本去研究新的弱點(發現新的利用手法)
- 當Codebase變得相當大,分析工作的難度會急遽上升
- 基於深度學習的自動化分析 : 主要用來克服人工定義、辨識Bug pattern的困難,但往往無法發揮很好的效果 :
- 對於整體上下文的理解不足 : 深度學習在一個單位內通常只能處理少部分的程式碼片段(基本上大多數時候涵蓋範圍不會超過一個函數),但記憶體漏洞通常會需要對多個函數的行為做分析 (例如經典的Heap選單題),很多Bug難以透過分析一個小片段就去斷言是否存在,例如RNN或是NLP,他們就不是為了拿來處理這類問題的。
- 難以捕捉多粒度特徵 : 如同上一點說的,但有人想到可以用AST這種控制流的圖丟給GNN學習。這樣的作法又引起另外一個問題 : 當你把整支程式的AST丟給一個GNN, 又會遇到GNN自己本身在大規模的圖難以克服的問題,例如Oversmoothing,或是難以學習長期相依性
- 錯雜流程圖的相關問題 : 不同類型的抽象化(CPG, SDG)的Edge定義不同,但基於GNN的方法又只是用一些很簡單的分類法,導致難以準確的捕捉語意
MVD+
結合小規模的學習(Code Slice)以及大規模(AST, CFG, …)的分析框架,解決了上述的三個問題 :
- 上下文 : 結合兩種分析方法(AST, Code Slice)去捕捉更多上下文特徵
- 多粒度 : 使用ASTNN來捕捉statement的語法,以及使用GNN來做statement之間的關聯性捕捉
- 錯雜流程圖 : 透過使用FS-GNN來處理不同類型的流程資訊,並學習不同關係之間的表示法
Preliminaries
一些名詞定義
- Code Snippet
- 一個Code Snippet由多個Statement組成
- 每個Statement又是由多個Token所組成
- Token : Variable, Constants, Operator/Operand, Keywords, …
- Code Slice : 對某個感興趣的語句(PoI),沿著SDG追蹤相關語句
- Forward Slice : 根據Data Dependency
- Backward Slice : Data + Control Dependency
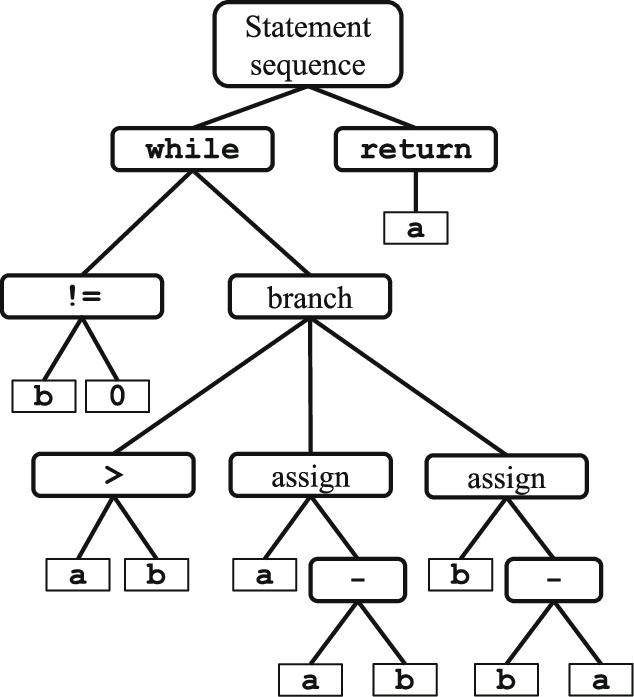
- Abstract Syntax Tree (AST)
- 用樹狀結構來表示程式語法
- 每個Node代表一個語法構建(Keyword, Operand, …),Edge代表整個結構的組合關係
- System Dependency Graph (SDG)
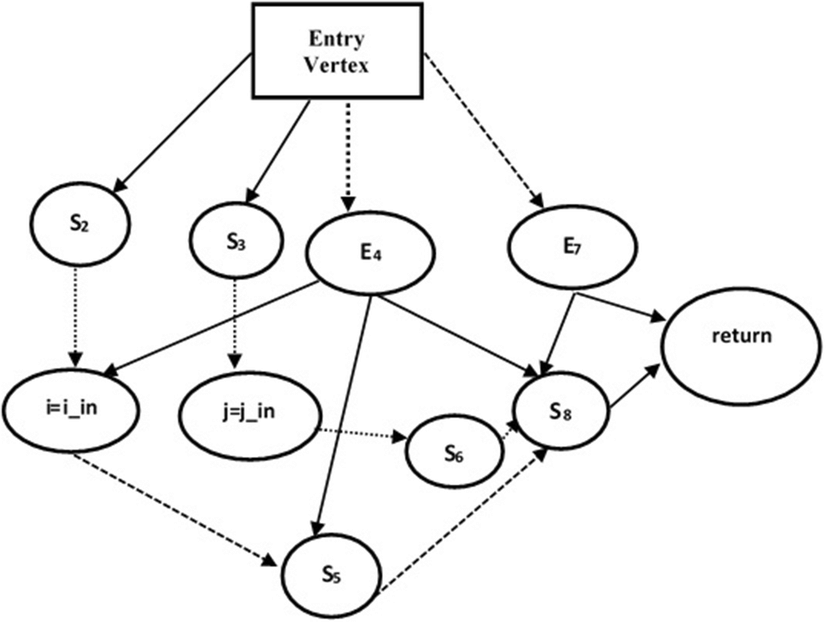
- 跨函數依賴圖,由多個不同的Program Dependency Graph (PDG)組成
- 每個Node代表一個Syntax,Edge代表控制/資料依賴 (判斷句/變數來源)
- Statement-level Vulnerability Detection
- 為MVD+的任務目標,對一個語句進行Binary Classification (是否有漏洞)
- 學習Statement set與Label set的函數,最終對每個語句輸出一個(有漏洞的)機率
- Tree-based Neural Network (TNN)
- TBCNN : 使用Convolution Kernel掃過AST,捕捉固定深度的語法特徵
- LSTM : 多分支的LSTM,可以根據每個Node的Recursive State來更新Parent
- ASTNN : 把大的AST切成小的Statement tree,然後再用RNN進行Recursive encoding (MVD+使用ASTNN)
- Graph Neural Network (GNN)
- 根據Neighborhood Aggregation去更新節點表示
- 每層把k-hop鄰居資訊聚合,用以表示資料/控制流
- 將圖分類問題轉化成節點分類問題,去標記一個Node(相當於一個Statement)是否存在漏洞
Experimentation
Overview of MVD+
MVD+ Overview:
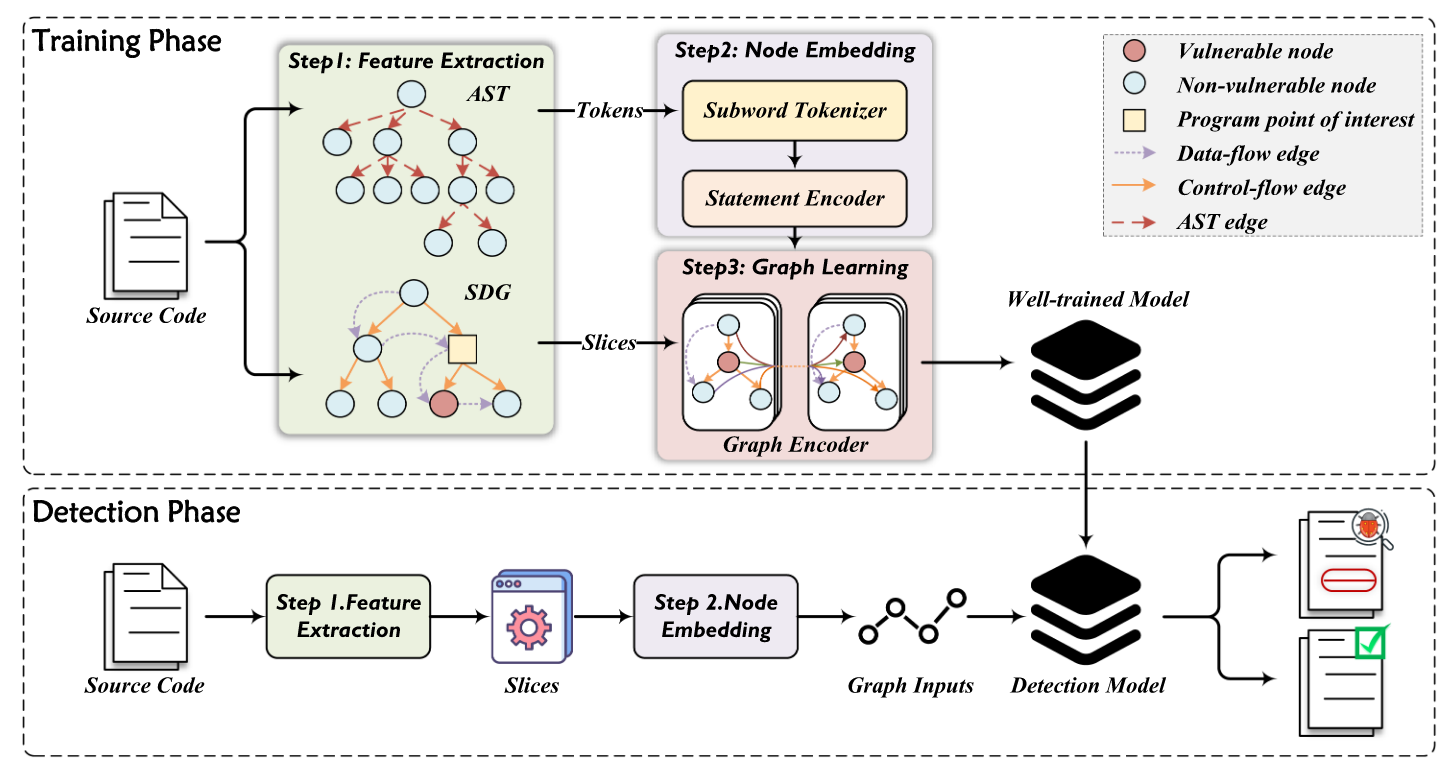
此框架的訓練流程大致上可以分成Feature Extraction以及Hierarchical Representation Learning
Feature Extraction
此階段的主要目標是把輸入資料(Source Code)轉化成結構化的表示,為接下來的分析做準備,其中大概可以再分成兩個部分 :
- Code Representation : 生成AST以及SDG
- AST用來表示語句以及函數的語法結構,捕捉程式碼中各個元素之間的語法關係(Grammatical Relations),最簡單的例子是運算元與運算子結合組成一個Expression
- SDG用來表示整支程式的控制/資料依賴,包含流程之間的依賴(例如 : 函數之間的呼叫關係、資料傳遞),對於記憶體漏洞分析非常重要,因為多數漏洞仰賴整體上下文理解(前面Existing Approach有提到)
- Program Slicing : 根據SDG去做Slicing
- 用來隔離最有可能發生漏洞的程式碼片段,來減少噪音對於分析過程的影響。此方法在一篇AAAI的論文中也有提到,該論文採用Temporal Max-Pooling去除掉無關部分, 以組合語言而言,每個函數都會有Prologue和Epilogue,但如果訓練的時候做池化時也把這些部分都放進去,則會造成訓練受到很大程度的影響(See Reference)
- MVD+使用興趣點來進行切片,比如記憶體漏洞中最常出現的malloc, free, memcpy等函數,從這些關鍵的API call在SDG上往回找,嘗試找到他的依賴 (資料從哪裡來/從哪裡呼叫到API),接著往下走,去蒐集有關聯的語句
Hierarchical Representation Learning
此階段的主要目的是對程式碼在不同粒度下的元素,去學習有意義的向量表示法,去解決多粒度特徵的問題,分為兩部分 :
- Node Embedding : 根據語句的結構做對應的表示
- 首先對token做嵌入,主要是用類似BPE的方法,MVD+採用微軟的CodeBERT
- 接著用ASTNN去處理每個語句的AST,因為ASTNN的設計就是會生成程式碼的對應向量表示(用AST對語法結構進行Recursive Encoding), 最終生成一個當前Graph Slice中所有Node(語句)的向量表示,用來捕捉語句的內部特徵
- Graph Learning : 側重在考慮語句和Slice裡面其他語句的關係來優化嵌入
- 使用FSGNN,因為傳統的GNN會隨著k-hop的k增加,產生指數級別的子集。FSGNN提出可以給每個特徵指定一個權重,讓模型進行特徵的軟選擇
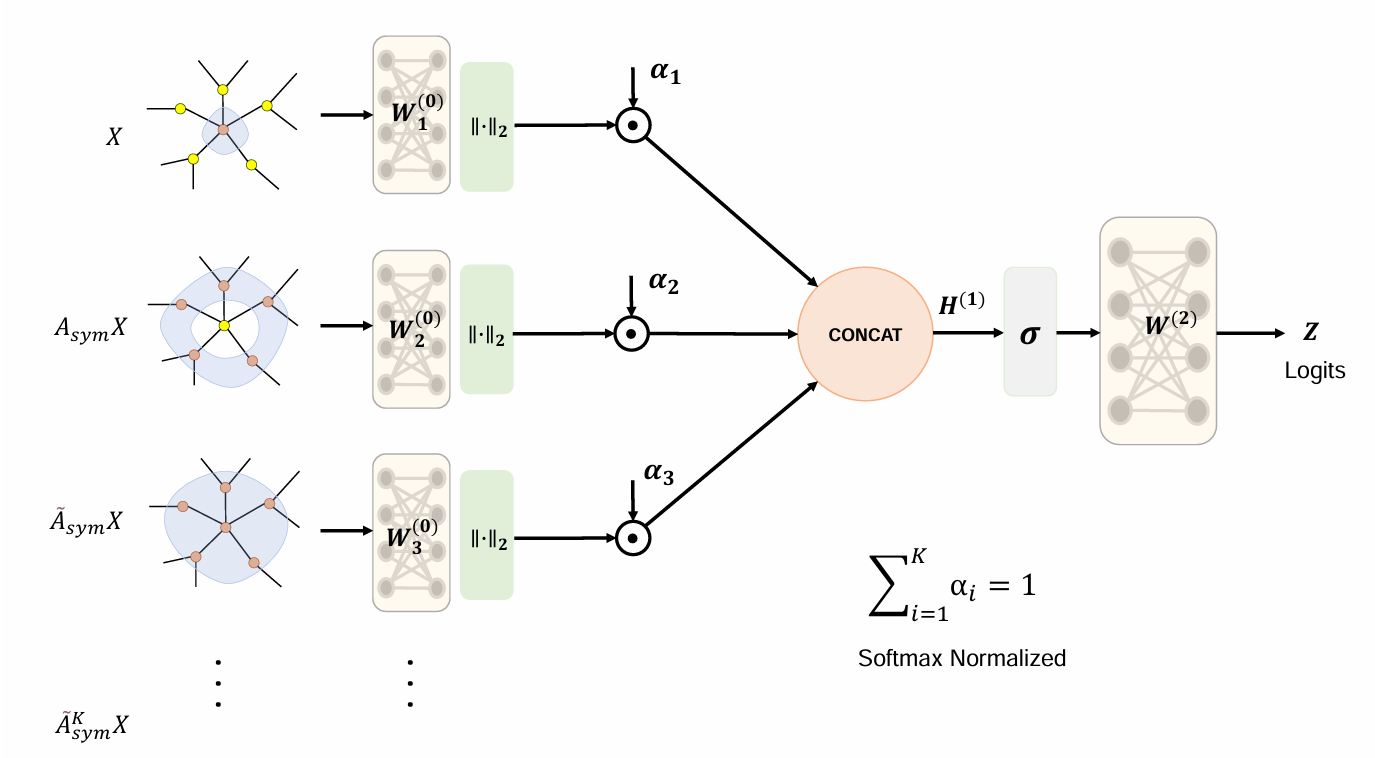
asd - 其中MVD+的FSGNN引入了GraphSMOTE重採樣,在只有少部分(通常來說都是少部分)有漏洞的語句下,提高分類性能
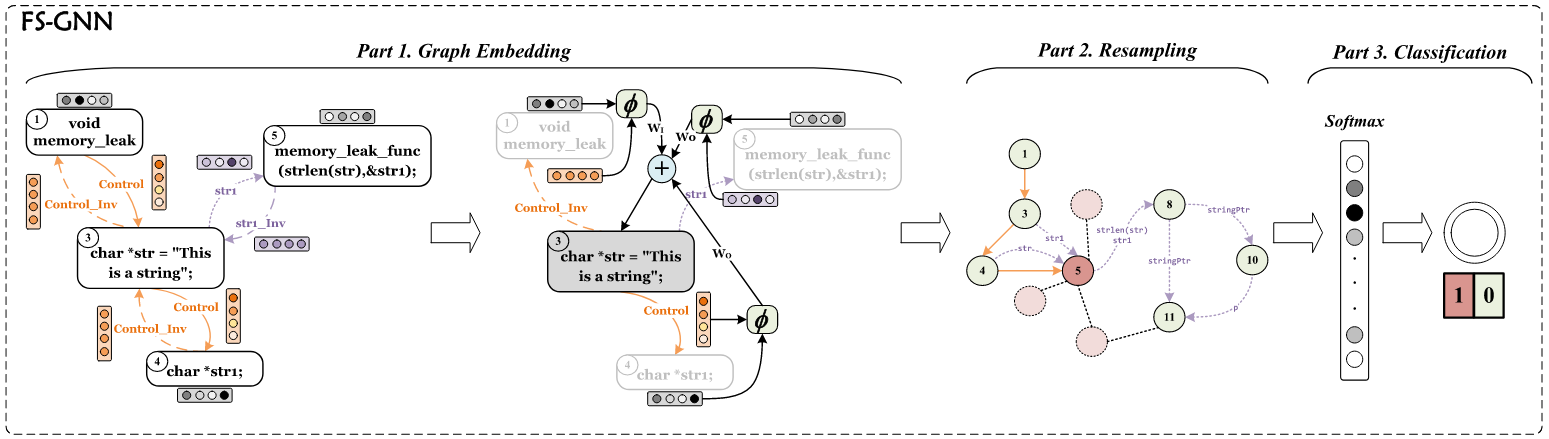
asd - MVD+使用Graph Slice作為FSGNN的輸入,其中每個節點都是一個語句,ASTNN生成的語句嵌入作為初始特徵,每個邊都是從SDG得到的依賴關係
- FSGNN透過圖的邊來做傳播,利用每個語句的表示,依據鄰居節點的表示以及依賴類型(控制/資料)去做更新。這樣能夠捕捉一個切片裡面的語句間上下文,假設這個切片剛好涵蓋多個函數,就能很好的解決錯雜圖的未充分利用問題
- 使用FSGNN,因為傳統的GNN會隨著k-hop的k增加,產生指數級別的子集。FSGNN提出可以給每個特徵指定一個權重,讓模型進行特徵的軟選擇
Experiment Setup
- Dataset : MemoryVul,包含SARD,CVE(Linux kernel, FFmpeg, …),並使用Statement-level Label
- Baseline
- DL-based : 基於RNN/LSTM/GRU : VulDeePecker, SySeVR ; 基於Transformer : LineVul ; 基於GNN : Devign, VulSeeker, IVDetect …
- Static Analysis (SA) : Flawfinder, RATS, Cppcheck …
- Metrics
- 使用標準的 Accuracy, Precision, Recall, F1-Score
- 針對不平衡資料的指標 : Matthews Correlation Coefficient, Precision-Recall Area Under Curve
- 排名指標 : Mean First Rank(需要檢查多少個語句才能找到第一個真正有漏洞的語句),Mean Average Rank(找到所有有漏洞語句的平均排名)
Results
- Effectiveness
- 相較於DL baseline : 在所有指標上都顯著優於目前的所有深度學習模型,針對GNN比較時最明顯,可以體現設計的有效性
- 相較於SA baseline : 在大多數指標,尤其是F1以及Recall上顯著優於所有靜態分析工具
- Efficiency
- 訓練時間 : 高於許多較簡單的DL baseline,但與一些複雜GNN模型相當,並可能低於一些大型Transformer
- 檢測時間 : 與DL baseline的平均表現相當 ; 靜態分析工具的檢測時間差異很大
- Ablation Study
- 將完整的MVD+與一個變體進行比較,該變體僅使用過程內分析。移除inter-procedual分析後性能顯著下降,捕捉跨函數調用和資料流的上下文對於準確檢測許多記憶體漏洞至關重要,驗證了關於現有方法局限性的假設
- GraphSMOTE對於提升MVD+的性能起到了積極作用,通過在嵌入空間中為少數類生成合成樣本(因為漏洞通常只發生在特定幾個點)
- 通過區分不同類型的流(資料/控制),FSGNN能夠更全面的學Source Code的細粒度語義特徵,進而更好地捕捉語句之間的結構化語義關係,所以顯著提高了檢測性能
Discussion
Case Study : CVE-2021-42739
此案例就是典型的”跨越多個函數”漏洞,涉及大量的上下文
這是一個Linux Kernel驅動的Heap Overflow,根據文獻可以在 firedtv-ci.c#L122找到相關的呼叫 :
static int fdtv_ca_pmt(struct firedtv *fdtv, void *arg){ struct ca_msg *msg = arg; int data_pos; int data_length; int i;
data_pos = 4; if (msg->msg[3] & 0x80) { data_length = 0; for (i = 0; i < (msg->msg[3] & 0x7f); i++) data_length = (data_length << 8) + msg->msg[data_pos++]; } else { data_length = msg->msg[3]; }
return avc_ca_pmt(fdtv, &msg->msg[data_pos], data_length);}在最後的呼叫處,avc_ca_mpt 傳入了data_length,但這裡沒有對他做任何檢查,再繼續追到相關定義 firedtv-avc.c#L1091看一下他的實作 :
int avc_ca_pmt(struct firedtv *fdtv, char *msg, int length){ struct avc_command_frame *c = (void *)fdtv->avc_data; struct avc_response_frame *r = (void *)fdtv->avc_data; int list_management; int program_info_length; int pmt_cmd_id; int read_pos; int write_pos; int es_info_length; int crc32_csum; int ret;
if (unlikely(avc_debug & AVC_DEBUG_APPLICATION_PMT)) debug_pmt(msg, length);
mutex_lock(&fdtv->avc_mutex);
c->ctype = AVC_CTYPE_CONTROL; c->subunit = AVC_SUBUNIT_TYPE_TUNER | fdtv->subunit; c->opcode = AVC_OPCODE_VENDOR;
if (msg[0] != EN50221_LIST_MANAGEMENT_ONLY) { dev_info(fdtv->device, "forcing list_management to ONLY\n"); msg[0] = EN50221_LIST_MANAGEMENT_ONLY; } /* We take the cmd_id from the programme level only! */ list_management = msg[0]; program_info_length = ((msg[4] & 0x0f) << 8) + msg[5]; if (program_info_length > 0) program_info_length--; /* Remove pmt_cmd_id */ pmt_cmd_id = msg[6];
c->operand[0] = SFE_VENDOR_DE_COMPANYID_0; c->operand[1] = SFE_VENDOR_DE_COMPANYID_1; c->operand[2] = SFE_VENDOR_DE_COMPANYID_2; c->operand[3] = SFE_VENDOR_OPCODE_HOST2CA; c->operand[4] = 0; /* slot */ c->operand[5] = SFE_VENDOR_TAG_CA_PMT; /* ca tag */ c->operand[6] = 0; /* more/last */ /* Use three bytes for length field in case length > 127 */ c->operand[10] = list_management; c->operand[11] = 0x01; /* pmt_cmd=OK_descramble */
/* TS program map table */
c->operand[12] = 0x02; /* Table id=2 */ c->operand[13] = 0x80; /* Section syntax + length */
c->operand[15] = msg[1]; /* Program number */ c->operand[16] = msg[2]; c->operand[17] = msg[3]; /* Version number and current/next */ c->operand[18] = 0x00; /* Section number=0 */ c->operand[19] = 0x00; /* Last section number=0 */ c->operand[20] = 0x1f; /* PCR_PID=1FFF */ c->operand[21] = 0xff; c->operand[22] = (program_info_length >> 8); /* Program info length */ c->operand[23] = (program_info_length & 0xff);
/* CA descriptors at programme level */ read_pos = 6; write_pos = 24; if (program_info_length > 0) { pmt_cmd_id = msg[read_pos++]; if (pmt_cmd_id != 1 && pmt_cmd_id != 4) dev_err(fdtv->device, "invalid pmt_cmd_id %d\n", pmt_cmd_id); if (program_info_length > sizeof(c->operand) - 4 - write_pos) { ret = -EINVAL; goto out; }
memcpy(&c->operand[write_pos], &msg[read_pos], program_info_length); read_pos += program_info_length; write_pos += program_info_length; } while (read_pos < length) { c->operand[write_pos++] = msg[read_pos++]; c->operand[write_pos++] = msg[read_pos++]; c->operand[write_pos++] = msg[read_pos++]; es_info_length = ((msg[read_pos] & 0x0f) << 8) + msg[read_pos + 1]; read_pos += 2; if (es_info_length > 0) es_info_length--; /* Remove pmt_cmd_id */ c->operand[write_pos++] = es_info_length >> 8; c->operand[write_pos++] = es_info_length & 0xff; if (es_info_length > 0) { pmt_cmd_id = msg[read_pos++]; if (pmt_cmd_id != 1 && pmt_cmd_id != 4) dev_err(fdtv->device, "invalid pmt_cmd_id %d at stream level\n", pmt_cmd_id);
if (es_info_length > sizeof(c->operand) - 4 - write_pos) { ret = -EINVAL; goto out; }
memcpy(&c->operand[write_pos], &msg[read_pos], es_info_length); read_pos += es_info_length; write_pos += es_info_length; } } write_pos += 4; /* CRC */
c->operand[7] = 0x82; c->operand[8] = (write_pos - 10) >> 8; c->operand[9] = (write_pos - 10) & 0xff; c->operand[14] = write_pos - 15;
crc32_csum = crc32_be(0, &c->operand[10], c->operand[12] - 1); c->operand[write_pos - 4] = (crc32_csum >> 24) & 0xff; c->operand[write_pos - 3] = (crc32_csum >> 16) & 0xff; c->operand[write_pos - 2] = (crc32_csum >> 8) & 0xff; c->operand[write_pos - 1] = (crc32_csum >> 0) & 0xff; pad_operands(c, write_pos);
fdtv->avc_data_length = ALIGN(3 + write_pos, 4); ret = avc_write(fdtv); if (ret < 0) goto out;
if (r->response != AVC_RESPONSE_ACCEPTED) { dev_err(fdtv->device, "CA PMT failed with response 0x%x\n", r->response); ret = -EACCES; }out: mutex_unlock(&fdtv->avc_mutex);
return ret;}其中最關鍵的部分在寫入的時候 :
// ... while (read_pos < length) { c->operand[write_pos++] = msg[read_pos++]; c->operand[write_pos++] = msg[read_pos++]; c->operand[write_pos++] = msg[read_pos++]; es_info_length = ((msg[read_pos] & 0x0f) << 8) + msg[read_pos + 1]; read_pos += 2; if (es_info_length > 0) es_info_length--; /* Remove pmt_cmd_id */ c->operand[write_pos++] = es_info_length >> 8; c->operand[write_pos++] = es_info_length & 0xff; if (es_info_length > 0) { pmt_cmd_id = msg[read_pos++]; if (pmt_cmd_id != 1 && pmt_cmd_id != 4) dev_err(fdtv->device, "invalid pmt_cmd_id %d at stream level\n", pmt_cmd_id);
if (es_info_length > sizeof(c->operand) - 4 - write_pos) { ret = -EINVAL; goto out; }
memcpy(&c->operand[write_pos], &msg[read_pos], es_info_length); read_pos += es_info_length; write_pos += es_info_length; } }// ...總共會做length次寫入,然後根據函數的定義,他是一個參數,而這個參數又是我們可控的,因為我們是從fdtv_ca_pmt呼叫過來。因此攻擊者可以構造ioctl,
去對這塊記憶體進行非法長度的寫入。兩個函數拆開來看,並不能看出高危險性的漏洞,但是結合在一起之後卻會造成Heap Overflow,這也是傳統的DL-based架構難以找出的漏洞,不過MVD+卻能夠正確label他,體現了在多粒度上的表現優越
Related Works
- Detecting Kernel Memory Leaks in Specialized Modules with Ownership Reasoning
- Goshawk: Hunting Memory Corruptions via Structure-Aware and Object-Centric Memory Operation Synopsis
- SMOKE: Scalable Path-Sensitive Memory Leak Detection for Millions of Lines of Code
- MLEE: Effective Detection of Memory Leaks on Early-Exit Paths in OS Kernels
Reference
Some content may be outdated